Note
Go to the end to download the full example code.
Multi-experiment ABP inference¶
Infer a shared interaction model from multiple independent ABP experiments that differ in both particle number and box size.
Real experimental data often consists of several recordings made
under different conditions — different densities, confinements, or
observation windows. SFI can handle them natively: each experiment
is a separate TrajectoryDataset carrying
its own periodic box via extras_global, and all datasets are
concatenated into a single TrajectoryCollection
for joint inference. The inferred force law is global — it must
explain all experiments with the same parameters.
Note
This is an advanced example: the force is fit with the parametric
estimator (infer_force()) on a PSF parameterisation. For
multi-experiment inference with the linear estimators, see
custom_basis_demo in the main gallery; dataset pooling and
weights are covered in Trajectory data.
Tags
synthetic · overdamped · multi-particle · multi-experiment · nonlinear · interactions
System: aligning ABPs with varying conditions¶
All experiments share the same underlying ABP force law (self-propulsion + repulsion + alignment), but differ in:
Particle number N
Box size \(L_x \times L_y\)
This creates a spectrum from dilute to crowded conditions, which stress-tests whether SFI can recover a unique model.
from _gallery_utils.abp import make_abp_align_psf
from SFI.langevin import OverdampedProcess
dt_sim = 0.02
Nsteps = 2000
D_iso = 0.05
seed = 42
# Shared exact force parameters
theta_F_exact = dict(c0=1.0, eps=2.0, A=0.5, R0=1.0, L0=2.0)
# Three experiments: (label, N_particles, Lx, Ly)
experiments = [
("Dilute / large box", 10, 30.0, 30.0),
("Moderate / medium box", 30, 20.0, 20.0),
("Crowded / small box", 60, 15.0, 15.0),
]
F_psf = make_abp_align_psf(dim=3)
Simulate each experiment¶
Each experiment produces its own trajectory collection with a
per-dataset box in extras_global.
collections = []
key = random.PRNGKey(seed)
for label, N, Lx, Ly in experiments:
box = jnp.array([Lx, Ly])
key, kx, kth, ksim = random.split(key, 4)
X0_xy = random.uniform(kx, (N, 2)) * jnp.array([Lx, Ly])
TH0 = random.uniform(kth, (N,), minval=-jnp.pi, maxval=jnp.pi)
x0 = jnp.concatenate([X0_xy, TH0[:, None]], axis=1)
proc = OverdampedProcess(F_psf, D=D_iso, extras_global={"box": box})
proc.set_params(theta_F=theta_F_exact)
proc.initialize(x0)
coll = proc.simulate(dt=dt_sim, Nsteps=Nsteps, key=ksim)
collections.append(coll)
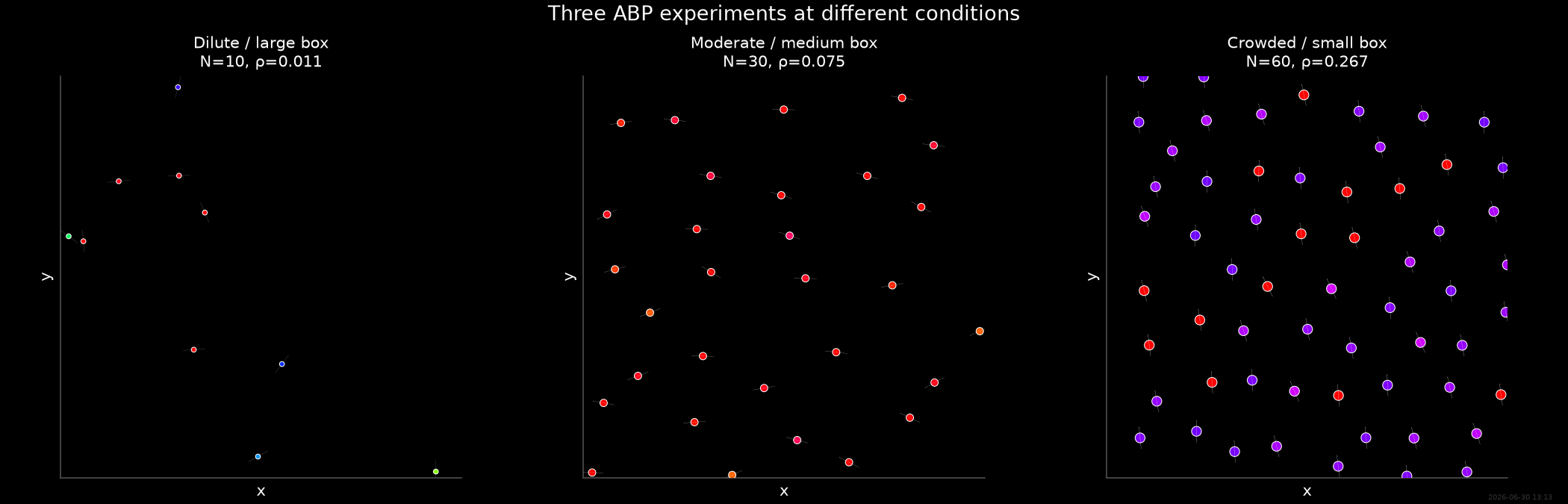
density = N / (Lx * Ly)
print(f" {label}: N={N}, L={Lx:.0f}×{Ly:.0f}, "
f"ρ={density:.3f}, frames={coll.T}")
Dilute / large box: N=10, L=30×30, ρ=0.011, frames=2000
Moderate / medium box: N=30, L=20×20, ρ=0.075, frames=2000
Crowded / small box: N=60, L=15×15, ρ=0.267, frames=2000
Snapshots from each experiment¶
Final-frame snapshots illustrate the different densities and box sizes. Positions are wrapped into the periodic box.
n_experiments = len(experiments) # panel count for the snapshot grid
Concatenate and infer¶
We merge all three collections into one and run a single nonlinear
(PSF) inference. SFI handles the per-dataset box automatically via
extras_global.
from SFI import OverdampedLangevinInference
# Merge trajectory collections with effective-temperature weighting
coll_all = collections[0].merge(collections[1:], weights="pool")
print(f"Combined: {len(coll_all.datasets)} datasets, "
f"weights = {np.asarray(coll_all.weights).round(3)}")
# Create inference object from the combined collection
inf = OverdampedLangevinInference(coll_all)
# Parametric force inference — the force law is shared across experiments
theta0 = jnp.zeros(F_psf.template.size) + 0.5
inf.infer_force(F_psf, theta0)
inf.compute_force_error()
Combined: 3 datasets, weights = [1. 1. 1.]
Inference report¶
The coefficient table now includes SNR and a significance
marker. Significant terms (|SNR| ≥ 2) are highlighted.
inf.print_report()
# Compare inferred parameters to the known ground truth
param_cmp = inf.compare_params_to_exact(theta_F_exact, psf=F_psf)
print(model_summary(
list(param_cmp),
[float(np.ravel(r["inferred"])[0]) for r in param_cmp.values()],
coeffs_true=[float(np.ravel(r["true"])[0]) for r in param_cmp.values()],
title="Parameter comparison",
))
--- StochasticForceInference Report ---
Average diffusion tensor:
[[ 4.9934786e-02 5.3933618e-05 -3.3197113e-05]
[ 5.3933618e-05 4.9718220e-02 8.9003232e-05]
[-3.3197113e-05 8.9003232e-05 4.9606975e-02]]
Measurement noise tensor:
[[ 4.7375120e-10 -1.5512473e-08 4.2456570e-08]
[-1.5512473e-08 5.1590968e-07 -1.5134789e-06]
[ 4.2456570e-08 -1.5134789e-06 6.8229469e-06]]
Force estimated information: 45065.30859375
Force: estimated normalized mean squared error (sampling only): 5.547490695456286e-05
Force Coefficient Table
──────────────────────────────────────────────────────────────
# Label Coefficient Std.Err SNR Sig
──────────────────────────────────────────────────────────────
0 b0 9.97974e-01 5.00600e-03 199.4 ***
1 b1 1.92416e+00 1.21947e-01 15.8 **
2 b2 1.03027e+00 4.76955e-02 21.6 **
3 b3 4.56689e-01 4.35565e-02 10.5 **
4 b4 2.08164e+00 1.03952e-01 20.0 **
──────────────────────────────────────────────────────────────
5/5 basis functions in support, sig: 5* / 5** / 1*** (|SNR| ≥ 2 / 10 / 100)
(Std.err. reflects sampling error only; discretization bias is not included.)
Parameter comparison
─────────────────────────────────────────────────────
# Label Coefficient True Sig
─────────────────────────────────────────────────────
0 c0 9.97974e-01 1.00000e+00 ·
1 eps 1.92416e+00 2.00000e+00 ·
2 A 4.56689e-01 5.00000e-01 ·
3 R0 1.03027e+00 1.00000e+00 ·
4 L0 2.08164e+00 2.00000e+00 ·
─────────────────────────────────────────────────────
5/5 basis functions in support
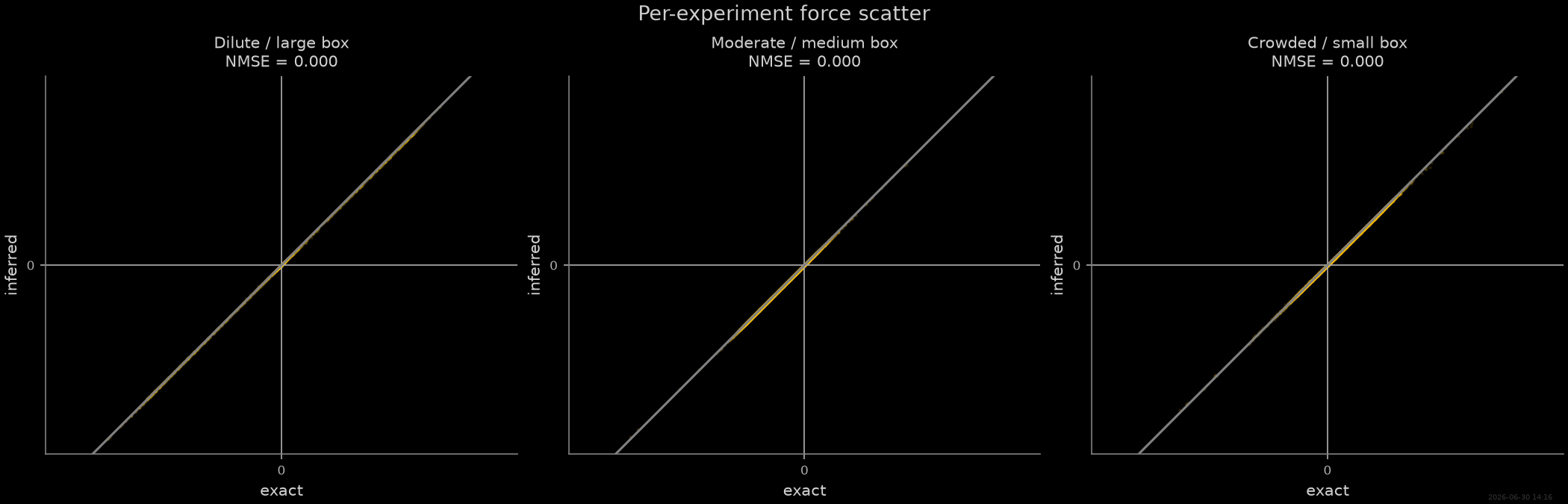
Per-experiment validation¶
For each experiment, evaluate the inferred force error separately. A good global model should explain all conditions, not just the average.
# Rebuild the exact force SF to evaluate ground-truth forces
exact_sf = F_psf.bind(theta_F_exact)
Animated multi-experiment snapshots¶
Side-by-side animation of all three experiments using the same inferred model — shown by bootstrapping trajectories.
n_frames = Nsteps // max(1, Nsteps // 150) # frame count for animation
Going further: experiment-specific parameters¶
Here the force law is fully shared — every experiment must be
explained by the same parameters. When part of the physics is
experiment-specific (a per-batch propulsion speed, a per-sample
temperature), keep the shared terms and add per-dataset parameters
through the reserved dataset_index extra (injected automatically
for every collection):
from SFI.bases import named_scalar, per_dataset_scalar
v0 = per_dataset_scalar("v0", n_datasets=len(collections)) # per experiment
k = named_scalar("k_align", default=1.0) # shared
# ... compose v0 and k into the force model, then inf.infer_force(F)
The parametric estimator fits shared and per-dataset parameters
jointly (L-BFGS path). On the linear estimators, the same idea is
expressed with one-hot features — dataset_indicator(n) * feature
gives an independent coefficient per experiment. See the
multi-experiment section of Trajectory data.
To reproduce one experiment from a pooled fit, bootstrap it with
dataset=k. The pooled model is collapsed to that condition (its
per-dataset parameters folded at k via inf.force_inferred.specialize)
and the returned process and trajectory are standalone — they carry no
dataset_index, so re-inference uses a plain single-condition basis:
coll_k, proc_k = inf.simulate_bootstrapped_trajectory(key, dataset=k)
# proc_k is experiment k's own model; coll_k is a clean single trajectory
stamp_output()
[Generated: 2026-06-30 14:19]
Total running time of the script: (65 minutes 57.841 seconds)